
数据结构 哈希表,二叉查找树 堆 优先队列-数据结构哈希表二叉查找树堆优先队列
title: 数据结构 哈希表,二叉查找树 堆 优先队列
url: 'https://yayi.site/archives/数据结构哈希表二叉查找树堆优先队列'
categories: 算法与设计
cover: 'https://cdn.jsdelivr.net/gh/TangxinGH/picbed/img/动漫/結城友奈は勇者である/犬吠·埼 樹.png'
tags: '二叉查找树,堆,优先队列'
abbrlink: 8a54951b
date: 2020-09-21 19:18:31
updated: 2021-05-14 22:04:55
数据结构
树
二叉树
二叉树的遍历方法:广度 深度。层次遍历。
链表
链表是最基本的线性数据结构。特点:逻辑上连续,物理(内在地址)上不一定连续。
在java中可以使用引用来实现结点的联结。c++直接用。
在内存的 不一定是物理线性的。
只能顺序访问。 插入,删除,增加,
双向链表
链表反转:
=修改指针的指向
1>2> 3> 4> 5 变成 5> 4> 3> 2> 1数组
An array is a container object that holds a fixed number of values of a single type. The length of an array is established when the array is created. After creation, its length is fixed. You have seen an example of arrays already, in the main method of the “Hello World!” application. This section discusses arrays in greater detail.
Each item in an array is called an element, and each element is accessed by its numerical index. As shown in the preceding illustration, numbering begins with 0. The 9th element, for example, would therefore be accessed at index 8.
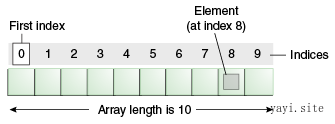
==本质==:一个顺序存储的线性表。可以用于存储多个数据。第个数据称 为 数组元素。
在java 中数组是一种引用类型。
数组初始化,无论是静态还是动态创建 ,都要指定长度
静态: 是直接赋好值。动态是 :先指定长度,运行时再填数据。
动态长度都 是链表,或者集合类型的数组。
百度一下,你就知道。下标从零开始。因为物理原因。速度是最快的。随机访问。
栈
先进看后出
弹出,压入。
队列
FIFO 。百度吧。
哈希表
通常与k -v 储存。
hashmap(key) 传入key 取出value .
普通的储存的话。 一般是线性搜索 找到目标key ,时间与数据量成正比。哈希解决了这个问题
下面 size=4的数组:
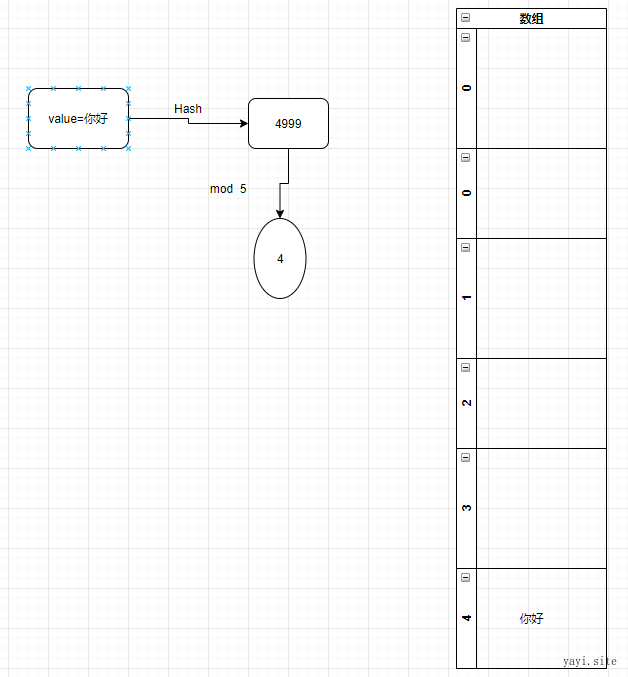
首先 将数据哈希函数计算后,得到哈希值,4999
然后再取mod 5 =4.所以存入位置4
这样,取出数据的时候对key 进行hash 得到 4999 再mod个size 。因为是数组嘛,直接 a[3] 这样访问,速度是很快的。而不需要像上面那样线性搜索。一个个对比。解决了速度问题。省了搜索。
同样的道理,存储其它进相应位置。
但是,hash的时候可能会出现同样 mod 5 =4 的情况。如 xxxyy mod 5 =4. xxx mod 5 也等于 4 。这时候有很多方法。
以链表形式:
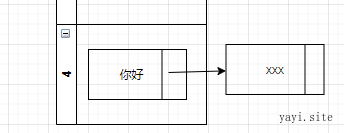
如果有多个就多链几个。
取出来时 ,不是链表的直接返回value 。有多个的 则 先 上面的计算 知道在 4 这个位置 。然后 取出 你好 和 xxx (单向链表是依次取,依次对比)相应的 key 与要寻找的目标key 值 对比 。是否相等。
==因为key是唯一的== 所肯定能找到
总结: 数组大点 。
堆
是一种树形结构。并在实现优先队列(一种数据结构)时使用。
优先队列:放入值时 任意顺序。取出时,优先取最小的。
堆:子类数字总是大于父类数字。
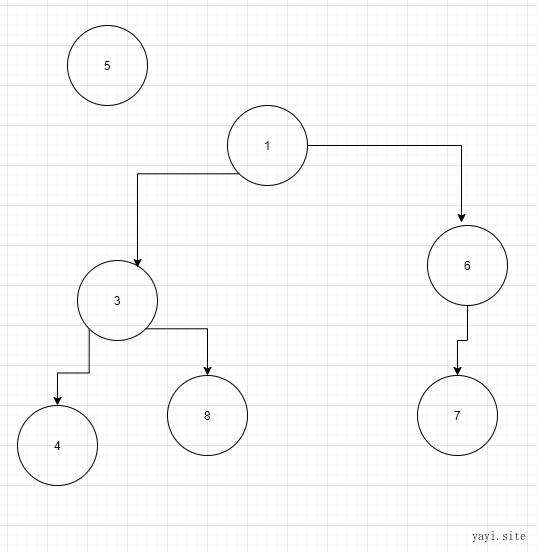
堆:首先添加的数字首先放在末尾。
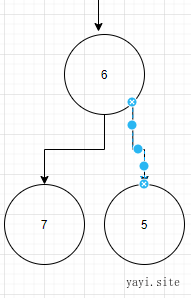
如果 父类的数字较大,则子类与父类互换。重复这个操作。
==所最小值总是在顶部==。也就是根结点。
当顶部的最小值 1 被取出时。需要==重新组织堆==的结构
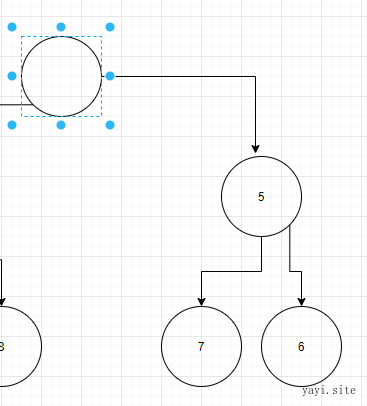
将结尾的数字移动 到顶部。也就是 6 到顶部。然后同样的,大于的则比较交换(父类6 > 右侧子类5> 左侧子类3 )。这个6 ,直到不再发生交换。此时堆已经有序了。
现在 3 在根结点了
缺点:无法执行在树中间 取出数据的操作。因为会破坏结构。
主要用于 优先队列 和戴克斯特拉算法。
优先队列就是取出堆数据后,重新排列堆,以便下次取出的还是最小的。
二叉查找树
有编号的点称为结点。
二叉查找树有两个属性:
- 所有节点都比左子树中的节点大 。 如15 比 9 3 12 8 都大
- 所有节点都比右子树中的节点小。如15 小于23 17 28
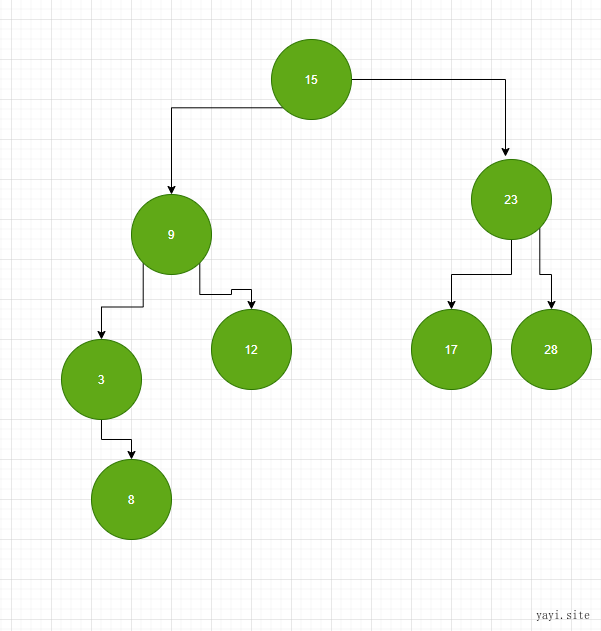
由于这两个属性,下列结论成立:
二叉查找树 最小节点位于最顶端节点的最左边的子树行的末尾 。
也就是3 是最小的
同样的道理。二叉查找树最大节点 位于最顶端节点的最右边的子树行的末尾。
也就是 28 是最大的。
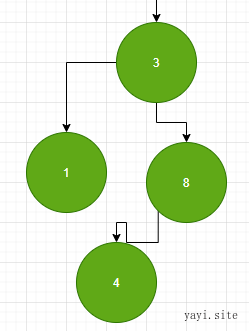
下面是添加节点的过程:
添加 数字 1 进去。
从最顶端节点开始开始。由于 1<15 向左走。
1<9 继续向左走
1<3 继续向左走,但因为没有节点在前方,所以我们添加为一个新的节点。
接下来添加一个4 。同理。走到 4 > 3 时,向右走,4 < 8 4 作为新结点 左则
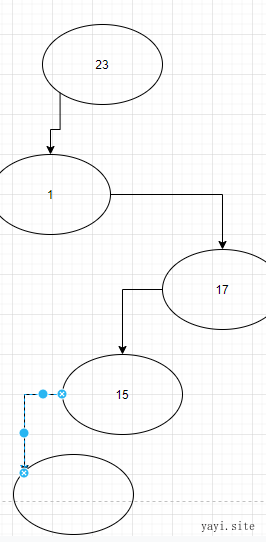
下面是删除节点过程:
- 删除目标28 。当节点 没有子结点的时候,直接删除就行。
- 删除目标8 。只有一个子结点时,直接删除,子结点填补上去。4补上去
- 删除目标9. 子结点有两个的时候,从删除节点的左子树找到最大 的节点。4补上去

怎么找最大值由属性结论给出。保留完整性。节点移动了也有它自己的子节点,那么递归 地重复相同的过程。
下面是搜索节点过程:
搜索12
从最顶部开始,12<15 向左走。大于则行右走。
12>4 向右走,没有路走,找到了12
可以看到==二叉查找 树可以实现 高效搜索==
但是,如果树形接近一条垂直的线,则效率就非常差了。变成了线性搜索
另一方面,如果一直保持良好平衡的二叉树称为==“自平衡二叉查找树”== ,能够保持搜索效率。可以参考红黑树
